Two approaches to science:
(Chapter 1 of Think Complexity provides a good overview of these two approaches).
Some systems may be very hard to accurately model, even though they may be deterministic.
Complex behavior arises from deterministic nonlinear dynamic systems and exhibit two special properties:
Most nonlinear dynamic systems are chaotic, and nonlinear dynamic systems constitute most of the dynamic systems we encounter. In general, systems involving flows (heat, fluid, etc) demonstrate nonlinear dynamics, but they also show up in classical mechanics (e.g. the three-body problem, the double-jointed pendulum).
The equations that describe chaotic systems can't be solved analytically - they are solved with computers instead.
Maps describe systems that operate in discrete time intervals.
In particular, a map is a mathematical operator that advances the system one time step (i.e. the next step). We describe them using a difference equation (not to be confused with differential equations, which come up later):
Where
The states (i.e. each of
There are different kinds of fixed points:
For example, if you drop the double pendulum, eventually it settles to a stationary position:
_____
|
|
0
This is an attracting fixed point.
There are other fixed points in this system. For example:
0
|
|
__|__
That is, the pendulum could be balanced on top, in which it would remain stationary, but easily disturbed, and this is not one that the system would settle into.
The time steps leading to a fixed point is called the transient.
The sequence of iterates is called an orbit or a trajectory of the dynamical system.
The first state
A common map is the logistic map,
It includes a parameter
Attractors are the states that remain after the transient dies out (i.e. after the system "settles"). Attracting fixed points are one kind of attractor, but there are also periodic (oscillating) and chaotic (strange) attractors.
A basin of attraction is the set of initial conditions which eventually converge on the same attractor.
One attractor is the (fixed) periodic orbit (also called a limit cycle) which is just a sequence of iterates that repeats indefinitely. A particular cycle may be referred to as an
A bifurcation refers to a qualitative change in the topology of an attractor. For example, in the logistic map, one value of
For example, with the logistic map: when
Often (1D/scalar) maps are plotted as a time domain plot, in which the horizontal axis is time
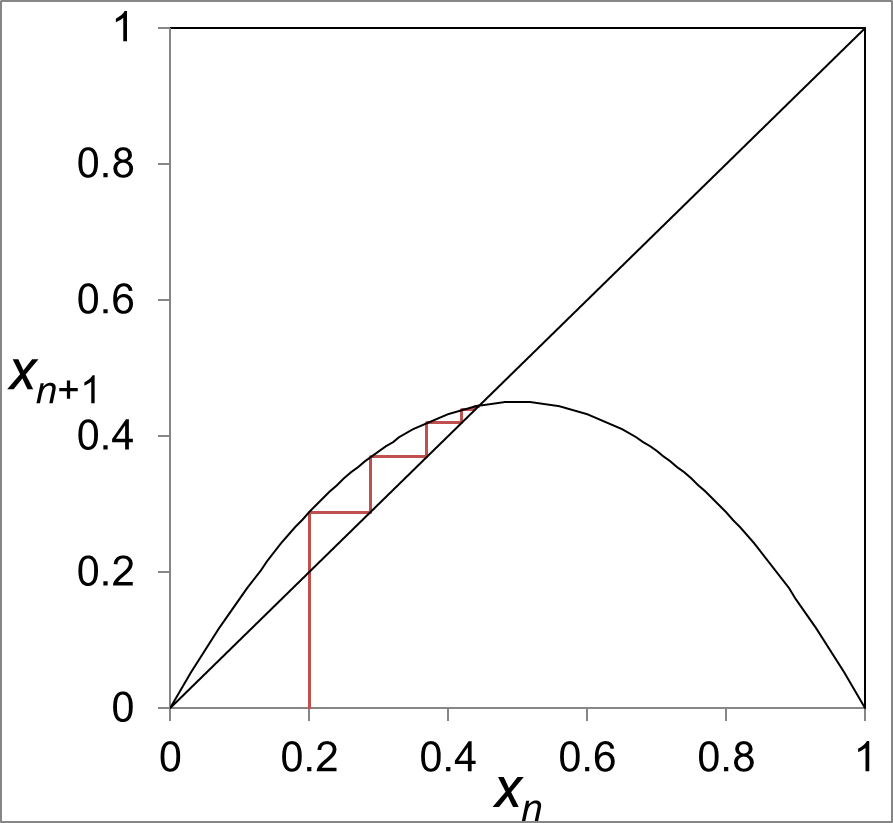
Another way of plotting them is using the (first) return map, also known as a correlation plot or a cobweb diagram, in which the horizontal axis is
On a return map, we also often include the line
A bifurcation diagram has as its horizontal axis
So for each value of
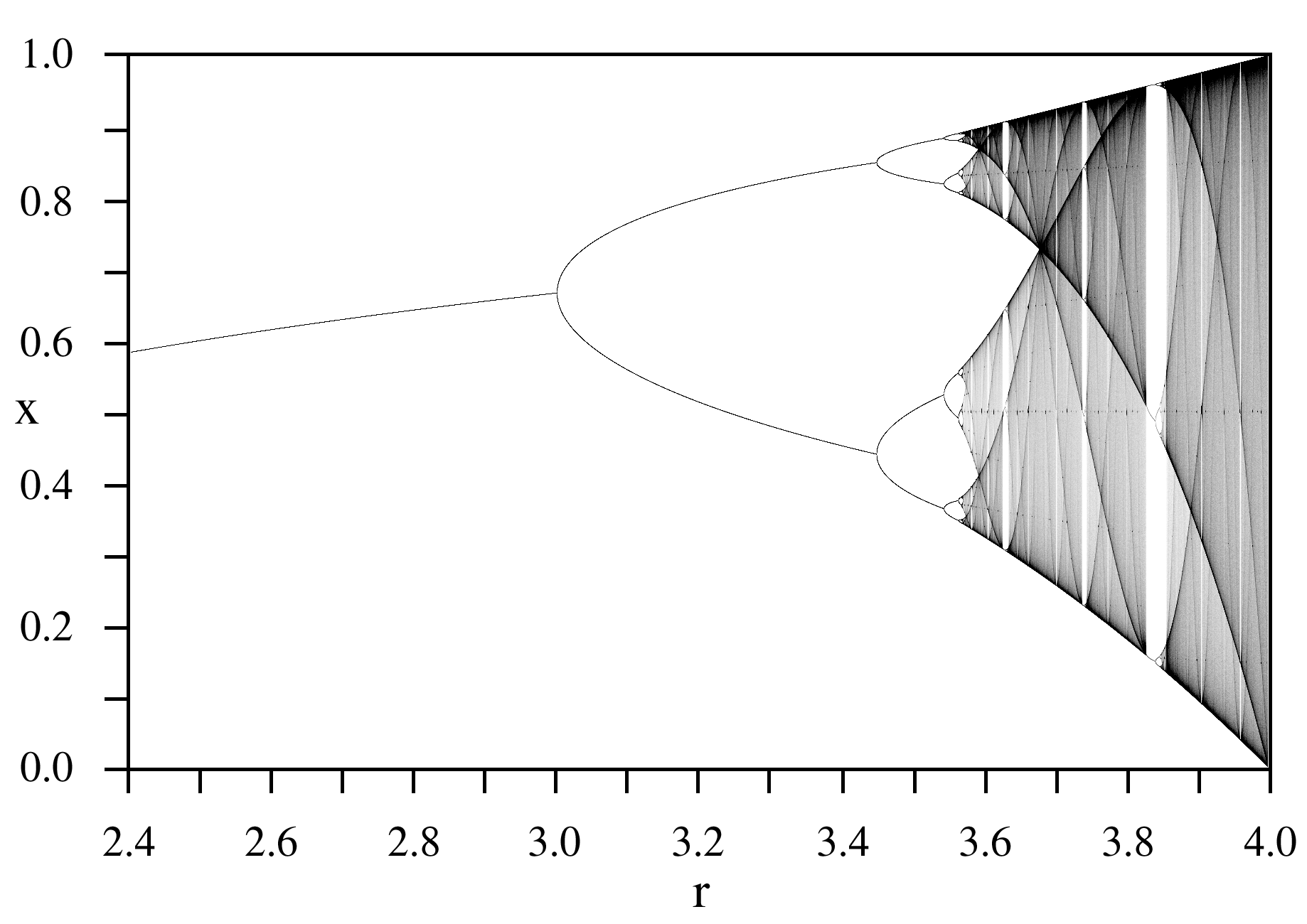
When looking at a bifurcation diagram, you may notice some interesting structures. In particular, you may notice that some periodic attractors bifurcate into period attractors of double the cycle (e.g. a 2-cycle period that turns into a 4-cycle period at some value of
You may also notice "dark veils" (they can look like thin lines cutting through) in the chaotic parts of the bifurcation diagram - they are the result of unstable periodic orbits.
The bifurcation diagram can also be a fractal object in that it can contain copies of itself within itself. For example, you can "zoom in" on the diagram and find its own structure repeated at smaller levels.
Note that many, but not all, chaotic systems have a fractal state-space structure.
If you look at the parts between bifurcations (the "pitchforks") in a bifurcation diagram, you may notice that their widths and heights decrease at a constant ratio.
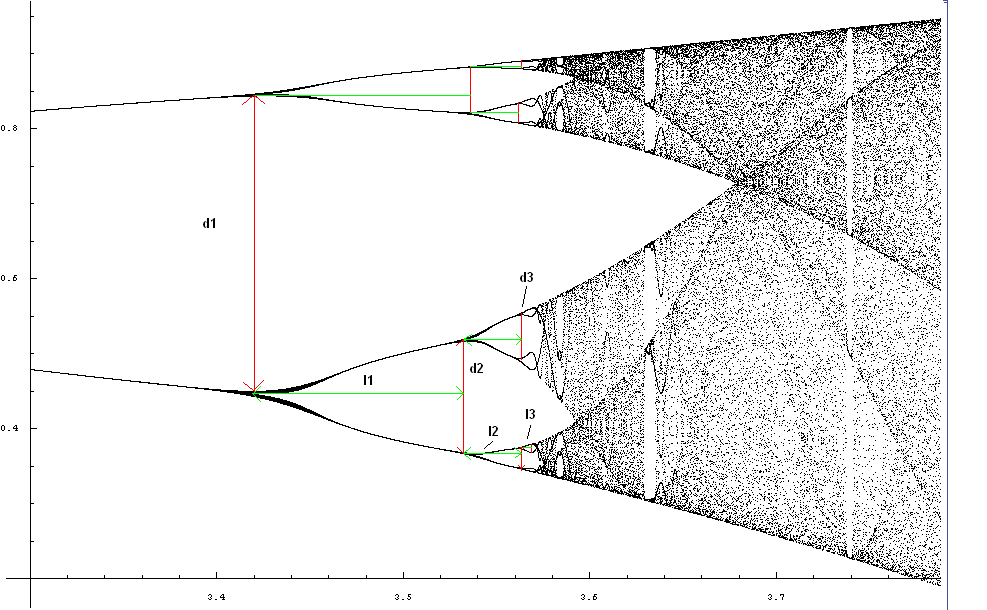
If we take
This value is called the Feigenbaum number, and it holds (as 4.66) for any 1D map with a quadratic maximum (i.e. it looks like a parabola near its maximum).
For the heights of these pitchforks there's a different value that's computed in a similar way.
One way of describing maps' property of sensitivity to initial conditions is that they bring far points close together and cause close together points to be pushed far away from each other.
One analogy is the kneading of dough. As you knead dough, parts that were close together end up far apart, and parts that were far apart end up close together (although if we consider the kneading as a continuous process, technically, this is a flow, but we can imagine it as discrete time steps).
Flows describe systems that operate in continuous time (e.g. the double-jointed pendulum). They are modeled using differential equations rather than difference equations.
All the concepts that apply to maps also apply to flows.
In the double-jointed pendulum, the state has four components: the angle of the top joint
A system without any friction (more generally, friction is known as dissipation) is called a conservative system or a Hamiltonian system or a non-dissipative system. These systems do not have attracting fixed points because there is nothing to cause the transient to die out. They do, however, still have fixed points - just not attracting ones - and they still have chaos - just not chaotic attractors.
Conversely, dissipative systems are those that have attractors.
An ODE expresses relationships between derivatives of an unknown function.
For example:
The unknown function here is
To solve this, we know that the derivative of
Another example: say we have the ODE
This is an analytic solution (closed-form, i.e. can be written out finitely). In most case, we will not be solving ODEs analytically, but numerically. This is because ODEs that can be solved analytically are, by definition, not chaotic.
ODEs may be linear, which have the form of a sum of "constant times variable" terms, e.g.
Note that nonlinearity is a necessary condition for chaos. If the ODE is nonlinear, it's possible there may not be an analytic solution - this property is known as nonintegrability, and it is a necessary and sufficient condition for chaos. They must be solved numerically.
Technically, "nonintegrability" only applies to Hamiltonian systems, but here we will use it as a shorthand for "has no analytic solution" more generally.
With flows we can think of fixed points in terms of a "dynamics landscape", i.e. the topography of the system. We can think of stable fixed points as some kind of "bowl" that values "roll down". In contrast, an unstable fixed point could be either an upside-down bowl or a saddle.
Sidebar on some linear algebra: matrices can be applied to transform space, i.e. for rotations, scaling, translations, etc. A matrix of eigenvectors allows us to express the fundamental features of a landscape. A point that starts on an eigenvector stays on that eigenvector ("eigen" means "same"). An eigenvalue tells you how fast a state travels along an eigenvector and in what direction - specifically, the movement is exponential:
Say we have two crossing eigenvectors, one of which is associated with eigenvalue *):
s_1
|
v
|
--->-*-<---s_2
|
^
|
That is, we have a bowl shape.
If instead both eigenvalues were positive, we'd have an upside-down bowl.
If one were positive and one were negative, we'd have a saddle.
Of course in practice, the forms (bowl, upside-down bowl, saddle) are rarely this neat and tidy, but often we use these as (linear) approximations when looking locally (i.e. "zoomed in" on a particular region). When looking at a larger scale, we instead must resort to nonlinear mathematics - the eigenvectors typically aren't "straight" at larger scales; they may become curvy.
When a fixed point's unstable eigenvector (that is, the one moving away from the fixed point) connects to the stable eigenvector of another fixed point (that is, the eigenvector moving into the other fixed point), that is called a heteroclinic orbit. For example (the relevant part has double-arrows, the weird hump is meant to be a curve to show that these eigenvectors are linear only locally around each fixed point):
| |
v -->>-- v
| / \ |
---<-*->>-/ \-->>-*-<--
| |
^ ^
| |
On the other hand, if a fixed point's unstable eigenvector, in the large scale, loops back and connects to its stable eigenvector, that is called a homoclinic orbit.
/-<<--\
| |
| |
| ^
v |
| /
---<-*->>--/
|
^
|
We call these larger structures (i.e. when looking beyond just the local eigenvectors, but rather the full curves that connect them) the stable or unstable manifolds of a fixed point. They are like nonlinear generalizations of eigenvectors in that they are invariant manifolds; that is, a state that starts on one of these manifolds stays on the manifold. They start out tangent to the eigenvectors (which is why we just use eigenvectors locally), but as mentioned before, they "curve" out depending on the dynamics landscape.
Growth/movement along these manifolds is also exponential, like it is for eigenvectors.
If all manifolds are stable, you have a fixed point (some kind of bowl, roughly speaking, but nonlinear). If all manifolds are unstable, you have a fixed point (some kind of upside-down bowl, roughly speaking).
Also note: a nonlinear system can have any number of attractors, of all types (fixed points, limit cycles/periodic orbits, quasiperiodic orbits [not discussed in this class], chaotic attractors) scattered throughout its state space, but there is no way of knowing a priori where they are and what type they are (or even how many there are).
Every point in the state space is in the basin of attraction of some attractor. The basins of attraction and the basin boundaries partition the state space.
An
For example, take the ODE for a simple harmonic oscillator (a mass on a spring):
This is a 2nd-order ODE. We can break it down into 1st-order ODEs like so:
We have actually defined two first-order ODEs (that is, it is a 2D ODE system), which we can represent as a vector:
There are no derivatives on the right-hand side, which is how we want things to be. The derivatives are isolated and the right-hand side just captures the dynamics of the system. The vector on the left-hand side is called a state vector.
Here we started with a 2nd-order ODE so we only required one helper variable. More generally, for an
Note that at least 3 dimensions is necessary for a chaotic system.
The general form for an
(As a reminder,
The state variables can be represented as a state vector:
This system defines a vector field. For every value of
For linear systems, matrices can describe how a "ball rolls in a landscape" (e.g. bowls, saddles, etc). The description is only good locally for nonlinear systems, as mentioned earlier.
For example, consider the following 2D linear system expressed with ODEs:
This can be re-written as:
So the matrix
But with a nonlinear system, we cannot write down such a matrix
A differential equation
A difference equation
An ODE solver takes as input:
And gives as output an estimate of
There are different methods of doing this, but a common one is Forward Euler, sometimes just called Euler's method or "follow the slope" - as it says, you just follow the slope to the next point. But how far do you follow the slope? There may be a lot of "bumps" in the landscape in which case following the slope at one point may become inaccurate after some distance (e.g. it may "overstep"). Shorter steps are computationally more expensive, since you must re-calculate the slope more frequently, but gives greater accuracy. For an ODE solver, this step size is controlled via the
For Forward Euler, the estimate of
A related method is Backward Euler:
Where
Intuitively, this is like taking a "test step", computing the derivative there, moving back to the start, and then and moving based on the derivative computed from the test step.
Note that Forward Euler and Backward Euler have numerical damping effects. For Backward Euler, it is positive damping, so it acts sort of like friction; for Forward Euler it is negative. The results of these computational precision errors, however, are indistinguishable from natural effects, which makes them difficult to deal with.
Note that Forward Euler is equivalent to the first part of a Taylor series, which is also used to approximate a point locally:
There are also other errors such as floating point errors - e.g. truncation or roundoff errors, depending on how the are handled. This is common with sensors. These errors propagate/snowball as they are used as starting points for the next computation and so on.
Another numerical approximation method is the trapezoidal method which essentially takes the average of Forward Euler and Backward Euler, and it does better than both.
Adaptive time-step ODE solvers change their time step as they go in an attempt to minimize error. In very flat parts of the landscape, for instance, large time steps are fine, but in very rugged parts, smaller time steps are better. A challenge here is that we don't know what the landscape looks like in the first place, which is why we are using an ODE solver to begin with. However, there are some methods that try to work around this.
One way of doing this is to take a step of
The method that is most used in nonlinear dynamics is Runge-Kutta. It is similar to Backward Euler in that it takes test steps to get a sense of the landscape ahead. The "order" of Runge-Kutta is the number of test steps it uses, e.g. RK2 uses two test steps.
Collectively, Forward Euler, Backward Euler, trapezoidal, and the Runge-Kutta "clan" are known as single-step ODE solvers. Technically, Forward Euler is the same as RK1 and trapezoidal is RK2. Backward Euler is an implicit version of RK1, meaning that it looks ahead.
There are also multi-step ODE solvers, which essentially fit a curve to the last
In a way similar to adaptive time-step approaches, we can use different Runge-Kutta orders where appropriate throughout the landscape - in flatter/smoother regions, we may use RK2, whereas in more rugged regions we may instead opt for RK4.
There are also special solvers for conservative systems (Hamiltonian) such as planets in the solar system. These are called symplectic ODE solvers. And there are other families of ODE solvers beyond these.
The fact that ODE solvers typically make mistakes, even very small ones, should lead you to question - if chaotic systems are sensitively dependent on initial conditions, what good are these solvers for chaotic systems?
The shadowing lemma gives us the following assurance (for chaotic attractors): Every noise-added trajectory on a chaotic attractor is shadowed by a true trajectory. Note that this is for state noise, not parameter noise. Another caveat is that this is not true if the noise bumps the trajectory out of the basin.
Another way of saying this is that noise can bump you onto a trajectory you would have ended up on anyways, either backwards in time or forwards in time. Thus this still messes up your position in time, but a good solver with a small step size causes these time-shift effects to be fairly small in scale.
Remember that stable manifolds are those which "flow" towards a fixed point, and unstable manifolds are those that flow away from a fixed point.
You can think of the unstable and stable manifolds as manipulating the state space itself. For example, say you look at many initial points simultaneously in the state space and track how they move over time. What you are essentially observing is how the dynamics of the system transform the state space itself (since the state space is composed of these points).
We can use this to formally define dissipation: dissipation happens when the state space shrinks. Similarly, for attractors to exist, the state space action has to be a contraction (i.e. the points are being pulled into a fixed point).
Lyapunov exponents parameterize the "spreading" action of dynamics, i.e. the unstable manifolds. They are notated as
A negative
To get an attractor, shrinking has to be the dominant action of the Lyapunov exponents. That is,
To get a chaotic attractor, there must be some stretching so the system doesn't collapse on a fixed point - that is, there must be at least one positive Lyapunov exponent for a chaotic attractor. Note that this however is not a necessary and sufficient condition for chaos.
Note that we are interested in long-term dynamics of the system, so we typically define Lyapunov exponents as long-term averages where
As
If you have the equations, you can calculate Lyapunov exponents using the eigenvalues of the variational matrix (not covered here).
If you only have data, there are various algorithms that can be used to compute them.
A section is a cross-section of a space, thus reducing its dimensionality. In the context of nonlinear dynamics, they are often called Poincare sections. The slicing surface is referred to as a plane of section, often notated
Consider a landscape with a circular trench in it. This is equivalent to a stable periodic orbit - a ball would tend to fall into that trench and loop around in an orbit.
In contrast, consider a thin circular ridge, like the rim of a volcano. If a ball were placed on it and pushed in just the right way, it would circle the rim in a periodic orbit. However, it is unstable - a slight tap will send the ball off the rim.
Embedded within any chaotic attractor are an infinite number of unstable periodic orbits (UPOs).
So far we have been assuming that we know and can measure all the state variables, but that is seldom actually the case. Furthermore, measurements are seldom exact (they are almost always noisy), and even when they are, that measurement is just a projection of the full state space. For instance, the state space may be three-dimensional but we measure only a single scalar value.
This is problematic because trajectories that don't cross in the full state space are made to seem as if they are crossing in the projected space, which misrepresents the topology of the object and also violates the assumptions for the systems we are studying here.
So then, is it possible to get the original topology from the projection?
There are other issues as well:
A technique called delay-coordinate embedding (DCE) allows us to "undo" a projection, giving us a qualitatively identical copy of the original system.
The basic idea is to plot the data against delayed versions of itself.
The space in which we reconstruct the original system from a projection is called the reconstruction space, which has many dimensions
Thus each axis plots our projected data delayed by some time step
For example, say we have the following data:
| 1.3 | 0.1 |
| 1.2 | 0.2 |
| 1.0 | 0.3 |
| 0.8 | 0.4 |
| 1.1 | 0.5 |
| 1.4 | 0.6 |
| 1.6 | 0.7 |
Which we want to plot in a three-dimensional (
Our first point would simply be (1.3, 1.0, 1.1). The next point would be (1.2, 0.8, 1.4), then the next would be (1.0, 1.1, 1.6), etc.
Takens theorem states that:
For the right
$\tau$ and enough dimensions, the embedded dynamics are diffeomorphic to (i.e. has the same topology as) the original state-space dynamics.
So we must choose appropriate values of
In practice,
Note that two systems with the same topology may still look very different to a person. But many dynamical invariants are invariant under transformations that preserve topology - which is to say, preserving the topology preserves many properties we care about (such as Lyaponuv exponents).
However, an additional constraint of enough dimensions is also asserted by Takens theorem. Generally,
Elsewhere the constraint is reduced to
Note that these constraints for
A final requirement is that the measured quantity (our data) must be a smooth, generic function on the state space and must be uniformly sampled in time.
Topology is the study of shape, without concern for measurement (size does not matter). Only the number of pieces and holes matters.
(Geometry, on the other hand, is concerned with size and measurement, hence the metry in its name.)
If you can take a shape and transform it into another shape without breaking it into pieces, combining pieces, or adding/removing holes, they have the same topology. The mathematical transformation that accomplishes this is called a diffeomorphism.
The procedure for this is:
Some suggest choosing the second minimum of the curve to allow enough lag to fully unfold/expand the dynamics.
This is the main heuristic (no theoretical guarantees) for choosing
The standard technique for estimating
The basic idea is: if
In more detail: when two points are close together at some dimension
This is also just a heuristic (there are others) with no theoretical guarantees. We also can't use the value of
We can't brute-force the
As amazing as DCE is, there are still many challenges when applying it:
So in practice, the conditions for Takens theorem can seldom be fully satisfied.
Noise can interfere with the false nearest neighbors method for estimating
Generally you need on the order of
To deal with nonstationarity, you can repeat the analysis on chunks of your data to see if that affects the results.
General dimensions are presented as integers - e.g 1-dimension, 2-dimension, 3-dimension, etc.
But fractional dimensions, also called fractal dimensions, are possible as well.
First, consider a line, a square, and a cube. Consider what happens when you scale each side of each object by some value
For example, when you scale a line by
When you scale a square's sides by
When you scale a cube's sides by
A pattern starts to emerge - the exponent is the dimensions of the object:
| Object | # Copies |
|---|---|
| Line | |
| Square | |
| Cube |
Now consider a fractal such as the Sierpinski triangle:

When you scale the sides of the Sierpinski triangle by
There are two ways of defining fractal dimension: capacity dimension and correlation dimension.
The capacity dimension, also known as the box dimension, box-counting dimension, or Minkowski-Bouligand dimension, for an object is defined as:
The intuition is that the capacity dimension describes how many balls of size
This is similar to the procedure outlined above.
How can we estimate the capacity dimension of an object?
The definition capacity dimension can be rearranged to (dropping the limit):
We can estimate the capacity dimension by changing
There may be artifacts in this plot - for smaller epsilon values,
The correlation dimension avoids to more computationally-intensive approach for estimating capacity dimension.
This method is called the Grassberger-Proccacia algorithm.
We start by defining the pointwise dimension. We pick a point
We can tune the amount of computation we want to do (at the expense of accuracy) by deciding what number of points to average over.
Note that
Formally, we define
Where
Almost all methods for estimating Lyaponuv exponents assume the system is autonomous; that is, the direction that is dynamically downhill at a given point is always the same regardless of when or how the point got there.
A point is chosen on the trajectory of the system, then looks at that point's nearest neighbor, tracks the movement of both points and watches how the distance between them grows with time. The initial distance between the two is
Then this formula is used to compute
In practice, Wolf's algorithm is not used because of its sensitivity to noise (as mentioned earlier, noise will easily mess with what points are nearest neighbors).
This sensitivity can be mitigated by choosing multiple points and multiple neighbors instead of just one of each, and tracking them in parallel.
First, we pick a starting point on the trajectory, then draw a ball of radius
Then we figure out where each of these points moves next. Then we repeat the average distance measurement with these one time-step forward points (i.e. from the center point one time-step forward to the other points one time-step forward).
The ratio of the first average distance to the second average distance is called the stretching factor
We repeat this for many different initial points and many different time-step sizes. Then we plot the results on a curve of
Like with capacity dimension estimation, there is a scaling region in this graph that is the region of interest. When time is small, points don't have enough time to stretch out, and when time is very large, the points spread out everywhere as far as they can. So somewhere in the middle is the scaling region.
If we call the slope of the scaling region
You have to be careful in applying this algorithm though - you should not imagine an appropriate scaling region when there isn't one, or if the curve is unstable when you tweak the algorithm settings (e.g. the
Noise reduction for nonlinear systems can be quite tricky, but one approach you can use is from Farmer & Sidorowich.
The general idea is that we can imagine that noise as a blob around a "true" point. The true point is in the center of the blob but noise means the observed point may show up anywhere else in that blob.
If we know something about the dynamics of the system, we can look at a point backwards in a time (the point and noise blob on the left) and a point forwards in time (the point and noise blob on the right) and see how the dynamics of that system (in particular, transverse stable and unstable manifolds) squish that noise blob (shown in the middle). All three version of the data should be identical at the center time, so we can average them - graphically, this is the overlap region, which provides us a smaller noisy area, i.e. it reduces noise.
This works best if the manifolds are perpendicular, but it is only required that they are transverse.

There are other methods as well, some of which involve using the topology of the attractor.
Generally the first step with prediction of nonlinear dynamics is, as a preprocessing step, to first embed the data using DCE so that whatever approach you do use can more fully take advantage of temporal patterns.
There are many ways to try and make predictions about nonlinear systems, but a simple and remarkably successful one is essentially
The first technique is called Lorenz's method of analogues (LMA). Say you have a point
A simple but very effective enhancement is similar to those we have seen before - just to take multiple nearest neighbors, look where they all go, and average those next positions. This method is called