Machine learning and simulation for:
- Narrative: describing and understanding systems
- Exploration: exploring large spaces of possibilities
- Companion: ML as an assistant
I also design & develop games and simulations, some of which are games more in the traditional sense, like this one here, The Founder, a business management simulator about Silicon Valley.
While others are tools for decision-making and speculation, such as this recent one, a transit model for the Brazilian government.
How do we understand a system?
Something that I'm very interested in is how we come to understand a system - whether it be some social system like a country or a city, or an ecosystem of some kind, or an economy, or the Economy, or a computer program, or the internet, or a networked and distributed program, a public health issue, an agricultural system, etc.
Not only how we come to understand it, but how we come to understand it so well that we can think through problems involving that system in a deft and intuitive way, where we don't feel stuck or slow, but possible solutions come naturally and easily and so do their verification and implementation.
Representational Infrastructure
(Wilensky & Papert, 2006;2010)
What factors into how quickly and easily we can learn something new and become proficient at it?
Our capacity to understand and manipulate knowledge is contingent on how we represent that knowledge and the operations that are possible with it.
For example, say I were to ask you for directions to a place.
You could tell me the directions, step-by-step. Might be hard for me to remember though, so you or I might write those directions down. So then I could follow those directions one by one and arrive at my destination. What if one of the roads on that list is closed? These written directions don't give much help in finding a new route.
If you had drawn me a map, that might help a bit more. I'd understand the general direction I needed to go to, so when faced with a closed road, I could estimate how I needed to get around it. But this map is likely a quick sketch, and you haven't really filled in enough detail for me to easily find a way around. I'd have to walk around, trial-and-error, trying some roads, hoping they take me closer and not to any dead ends, to find a better route.
If you'd have given me a complete map and annotated with the route you wanted me to take, then I'm much better off. I can just use the paper to plot out alternative paths, saving me the effort of wandering around to find alternative routes. But some of these alternative paths may also have road blocks that aren't reflected on the paper map.
Of course nowadays we obviate the need of asking people for directions or messing about with paper maps, we use a service like Google Maps which takes care of the re-routing for us. However, the actual representation of the directions is more or less the same than what I've described already.
The point here is that different representations make operations easier or possible.
Compute the following:
XCVIII * LXXIX
When Wilensky and Papert discuss representational infrastructure, they use the example of Roman vs Hindu-Arabic numerals.
The computation above is really difficult to do with Roman numerals. It's likely that you first translated the Roman numerals into Hindu-Arabic numerals and then calculated the product.
Many operations that are relatively easy with Hindu-Arabic numerals are much more difficult to do with Roman numerals. The ease of Hindu-Arabic numerals has a lot to do with how it's structure around decimal places. So addition, for example, is easier, with the system of carrying numbers of to higher decimal places.
In fact, the awkwardness of Roman numerals for these simple operations may have contributed to the fact that only a highly-trained clergy could do mathematical operations we expect children be able to do well nowadays. With the proliferation of Hindu-Arabic numerals, these operations became more intuitive, better structured, and enabled easier processes for computing them.
(And like the maps example, nowadays we'd punch the product into a calculator and let that compute it, but again, the representational infrastructure remains the same).
(answer is 98 * 79 = 7742)
Representing a system
So the way we represent a concept, a system, a question, a problem, affects what we can think about it, and how we can think about it, and how easily we can solve it.
A question that falls out of all of this is: what representations are we currently relying on that are inadequate or clumsy, that can be improved upon?
Narrative
Describing systems to better understand them
Ways to describe systems
Ways to describe systems
- Mathematically, i.e. via equations
Ways to describe systems
- Mathematically, i.e. via equations
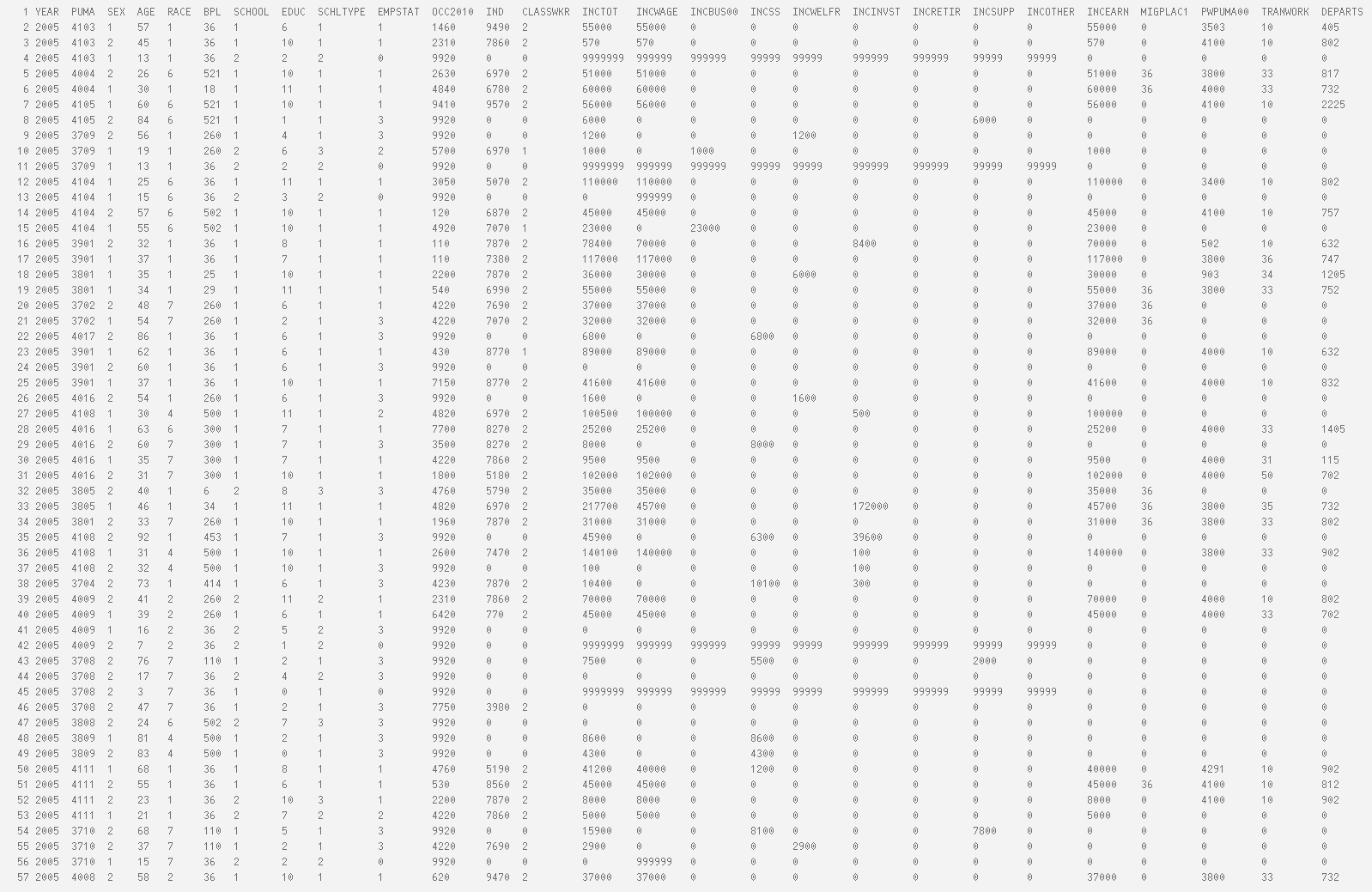
- Numerically, i.e. via a dataset
Ways to describe systems
- Mathematically, i.e. via equations
- Numerically, i.e. via a dataset
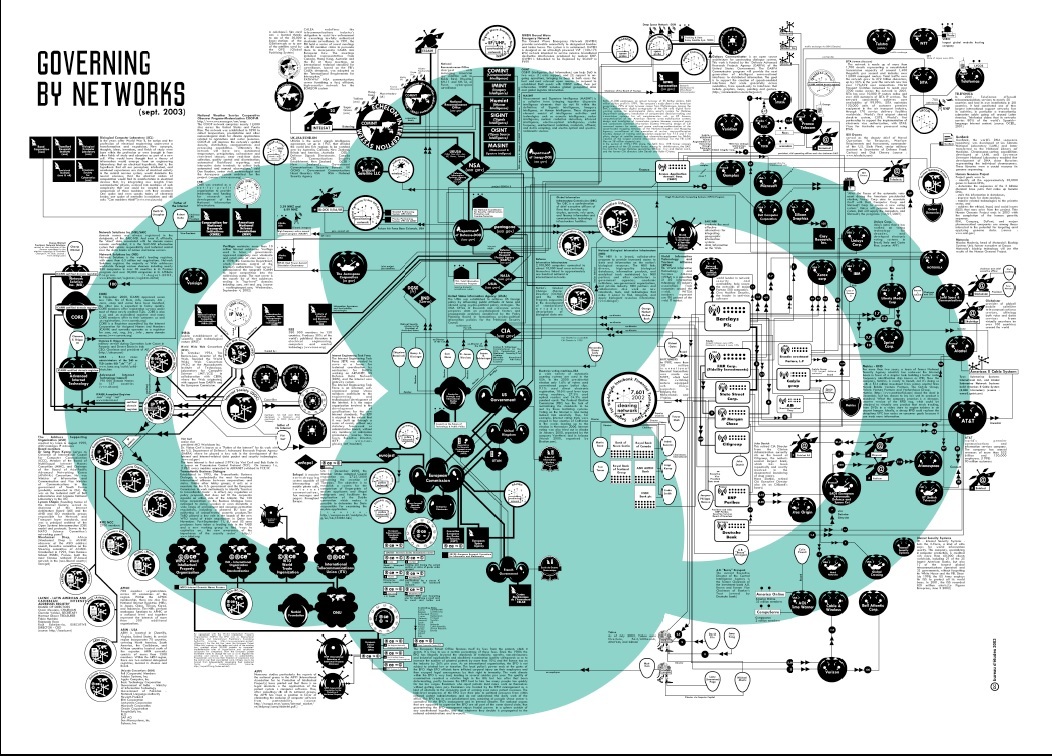
- Graphically, i.e. via images, charts, networks
Ways to describe systems
- Mathematically, i.e. via equations
- Numerically, i.e. via a dataset
- Graphically, i.e. via images, charts, networks
- Narratively, i.e. by a story, film, etc
Mathematical description

Numerical description
Graphical description
Narrative description

Narratives are especially compelling ways to represent systems; they require very little formal training (learn to read, or learn the language that's spoken) and they are arguably the primary way we learn. They inform how we make sense of the world. Through cinema, novels, journalism, and so on.

But what are the limits of narratives as we know it now? In terms of their ability to wholly and convincingly represent a system. Traditional narratives focus on roughly one story at a time, one thread out of potentially infinite possible stories, or even existing and overlapping stories, each with their own interesting variations and subtleties. How could you create an experience that has the capacity to tell all those stories, simultaneously?
We can think of stories as one thread in a space of infinite threads.
My collaborator Fei Liu and I had a bunch of this Census data, spanning roughly a decade, and we were interested in what stories it contained. Looking at that data, these stories are pretty obscured. You can run some statistical methods and get summaries of the dataset, but it does not viscerally demonstrate the experiences that constitute that data. We wanted to see if we could reconstruct some of these narratives from the data. Of course the data is not complete we have to insert some of our own assumptions but that was the general idea.
But it was our hope that we could take each of these rows in the dataset and transform them into a story that unfolds over time, together with the other people those rows represent, in a virtual city.
Humans of Simulated New York

The result was the project "Humans of Simulated New York". We applied a few machine learning techniques to "fill-in-the-gaps" so to speak, such as Bayesian networks for generating populations that are structurally similar to the Census data (i.e. reflect the patterns found in there) without directly using that data, and reinforcement learning for determining the behaviors of firms in the city's economies without having to manually program them all.
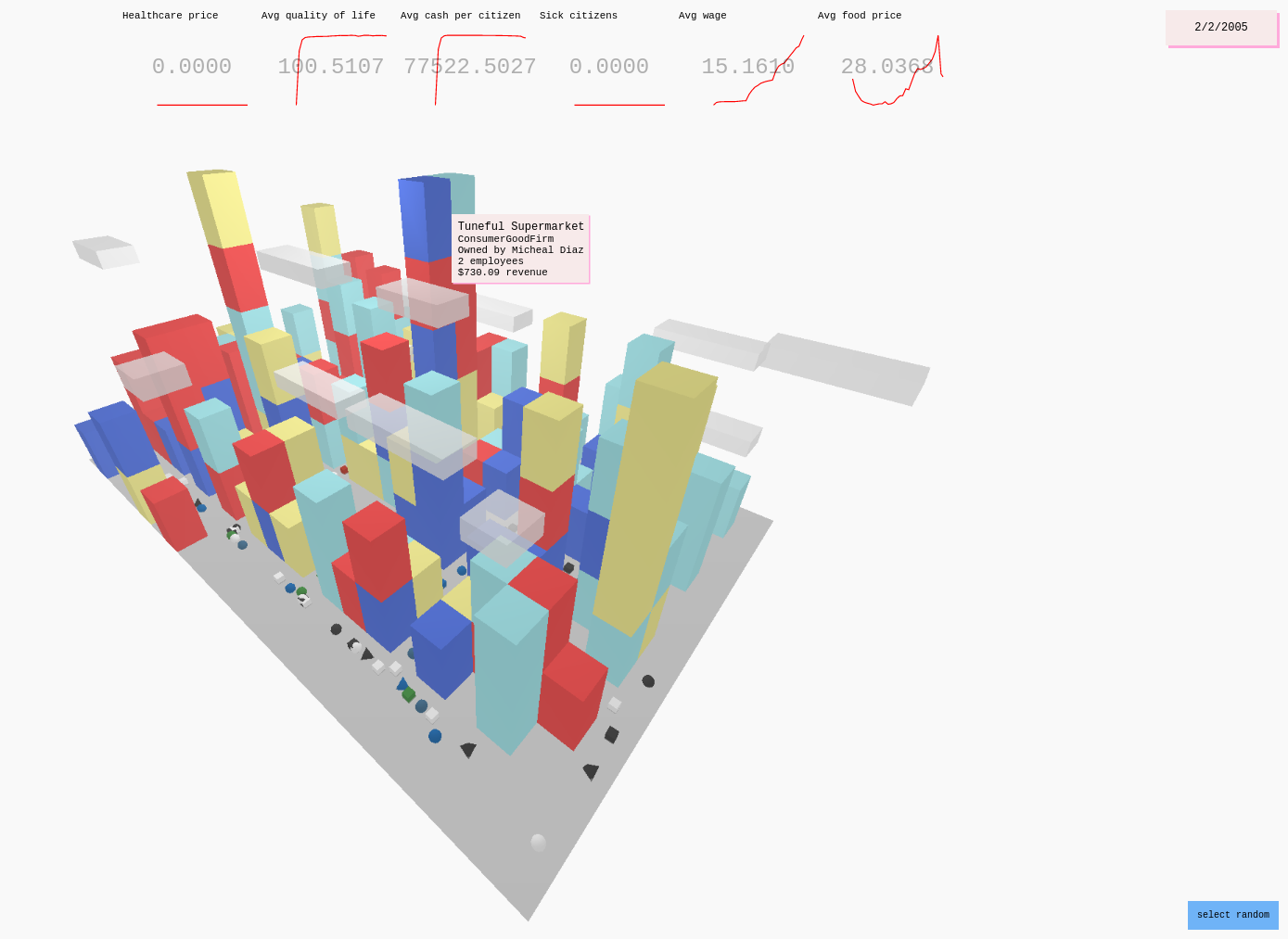
Each of these shapes is a citizen of the city, and they all have their own small history and preferences and personality. And each business has an owner, a name, and so on, all to add to the richness of the world. You can follow citizens around to see how they fare, if they are able to find work, or start a business, if they get sick, and so on.

Exploration
Once we come to understand a system better, how do we begin to explore all of its possibilities?
In a creative industry, ideation is a very important step. You have to come up with a lot of ideas very quickly, and have some process for whittling those down to the best ones. But you never know a priori which ones are the best ones, especially if they start out as just ideas. You need to make them into something a bit more substantial before you can be confident in what to cut and what to keep. That might involve sketching out an idea, or making a prototype, or filming a pilot. But these take time and resources. So it's typically infeasible to test out every idea to see what is worth following through on.
This is two-part problem here. The first part is coming up with the ideas. There is a space of potentially infinite possibilities, but it's not wise to try each possibility one-by-one. As humans, when we are experienced in a field, we develop intuitions on how to explore this space, we can make gut choices about what's worth trying and what's not. But even for someone experienced, this process of possibility exploration can be slow and laborious.
The second part is then vetting those ideas. Even with an expert estimating what's worth pursuing and what isn't, you still have to test those ideas, and that can also be slow and laborious. The expert can provide a good guess, but you still want to verify which is really the most promising.
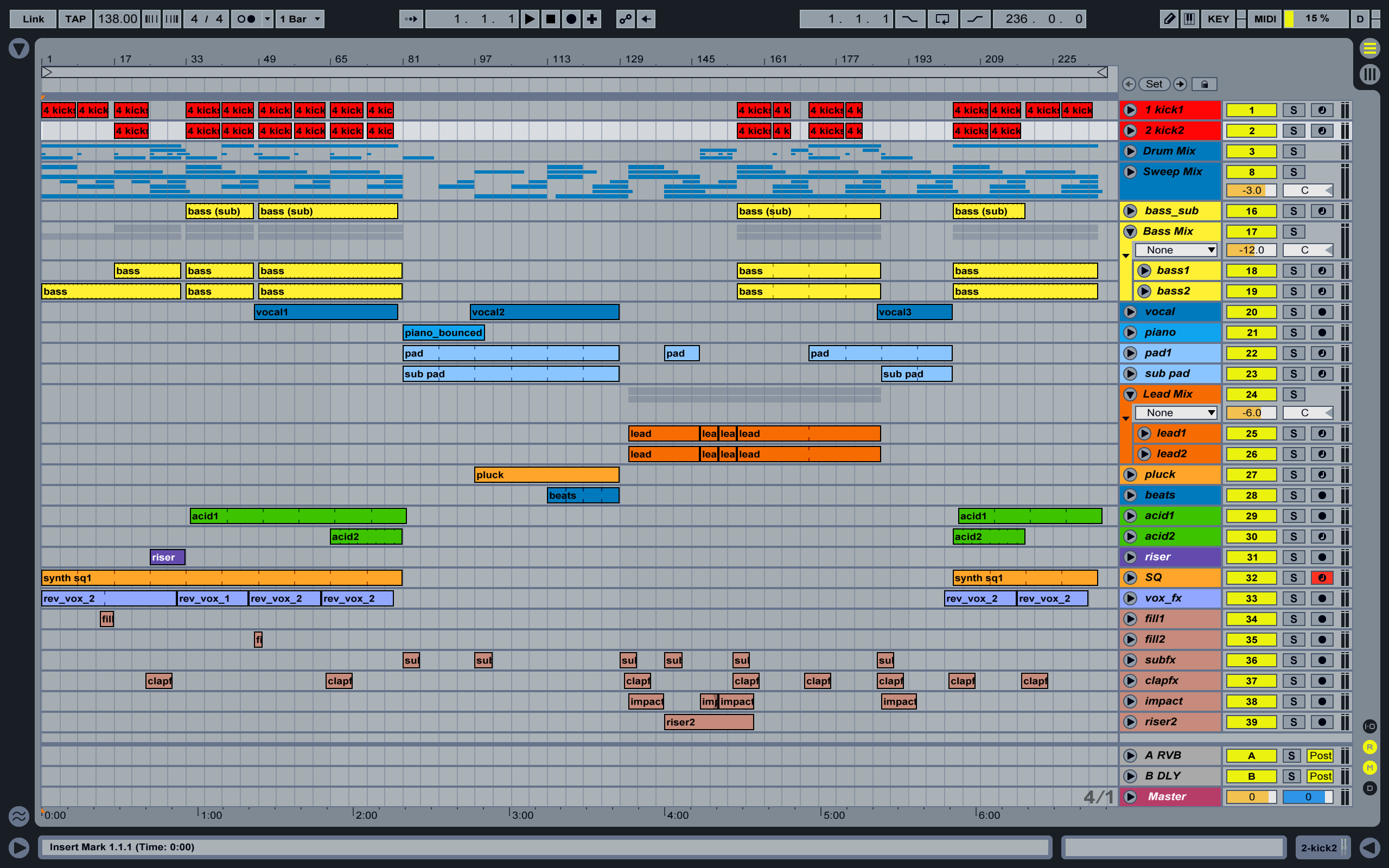
Some of the most interesting applications of AI are built around assisting in this search. I spent a few years as a musician, and combing up ideas was hard for me. At the time the kind of music I was interested in was a style called "plunderphonics", which involves searching through music, cutting out samples from tracks, and then stitching them together in interesting ways.
Finding the tracks can be a slow process, since there is just so much music to search through, and cutting up the tracks can be meticulous - they need to be cut synchronized with their rhythms, and those need to be manipulated to match other samples, and then you have to bring them into your music software and arrange them. Then you listen and see if it sounds good.
If not, you repeat a lot of this process until you're happy with the result. Maybe the tracks you're working with just aren't right, so you need to search for more. Or the samples you cut out aren't to your liking, so you cut different ones out of the track. And so on.
To give you an idea of how long this process can take, one band that specializes in this kind of music, The Avalanches, took 16 years between their first and second albums. There is just so much experimentation, variety, and uncertainty in the process that it takes a long time.
I thought it'd be much easier if I could just rapidly stitch together hundreds of tracks and just listen to them until something caught my attention. And then I could use that as a starting point.
So I wrote a program that would do this searching and experimentation for me. I called the program "Pablo" in honor of the first Avalanches album.
Basically what it would do is it would scour YouTube for music tracks, based on a track you suggested, pull that music and cut it up into samples of various sizes, then use a few naive heuristics for assembling as many sketch tracks as you wanted. Then you could sit back and listen to what it produced, noting parts you like, and then seeing what clips the program used to compose those tracks.
At the time I made Pablo, robust applications of machine learning to music were still pretty new. Now we have Spotify's recommended playlists which show that it's possible to compute song similarity fairly well. If I were to revisit Pablo I'd use some of these new methods to make it so that it would more intelligently assemble tracks, and over time, learn your preferences and start to focus on tracks that seem to fit those.
This same principle applies in domains beyond creative industries. There is some work, for instance, in public policy and economics (these focus less on the ideation side of the process on more on the verification side). With HOSNY, we wanted to do something similar, framing it as an economic tool to speculate with different economic outcomes for the city. There are more sophisticated tools used by urban transit planners as well to hypothesize the outcomes of new transit lines or changes to road networks.
This for example is a recent project I did with the Institute for Applied Economic Research in Brazil. We worked on an spatial economic model for the whole of Brazil and implemented a transit model as well, so we could estimate how economic policy changes might impact not only businesses and households but also transit networks.

And this for example is a project called "Highrise", for modeling architecture interiors to see how users of the building might behave. This project is more on the "verification" side of this creative problem, we didn't get to the point of implementing the ideation part which would rapidly iterate various interior designs to find ones that seem to mesh well with the expected users of the building.
I know that there is work on rapidly exploring the space of possible materials to search for new materials with specified properties. Similarly, I wonder if it's possible to explore the space of possible flavor molecules to search for novel and exciting new flavors.
“Finding new materials has traditionally been guided by intuition and trial and error,” said Lookman.“But with increasing chemical complexity, the combination possibilities become too large for trial-and-error approaches to be practical.”
To address this, Lookman, along with his colleagues at Los Alamos and the State Key Laboratory for Mechanical Behavior of Materials in China, employed machine learning to speed up the process. It worked. They developed a framework that uses uncertainties to iteratively guide the next experiments to be performed in search of a shape-memory alloy with very low thermal hysteresis (or dissipation). Such alloys are critical for improving fatigue life in engineering applications.
At last year's annual NIPS conference (Neural Information Processing Systems), one of the leading conferences for new machine learning research, a workshop called "Machine Learning for Molecules and Materials" was held, so it is quite an active area of research and interest.
Companion
This idea of machine learning as an explorer, as a creative assistant, is part of a broader notion of machine learning as a foundation for a new set of tools, or companions, rather than strictly as a method for deriving insights or analytics or forecasts from data.
Most of my experience with ML-based tools is with respect to journalism, so I'll speak mostly to that, but again, the ideas here are generalizable to other domains.
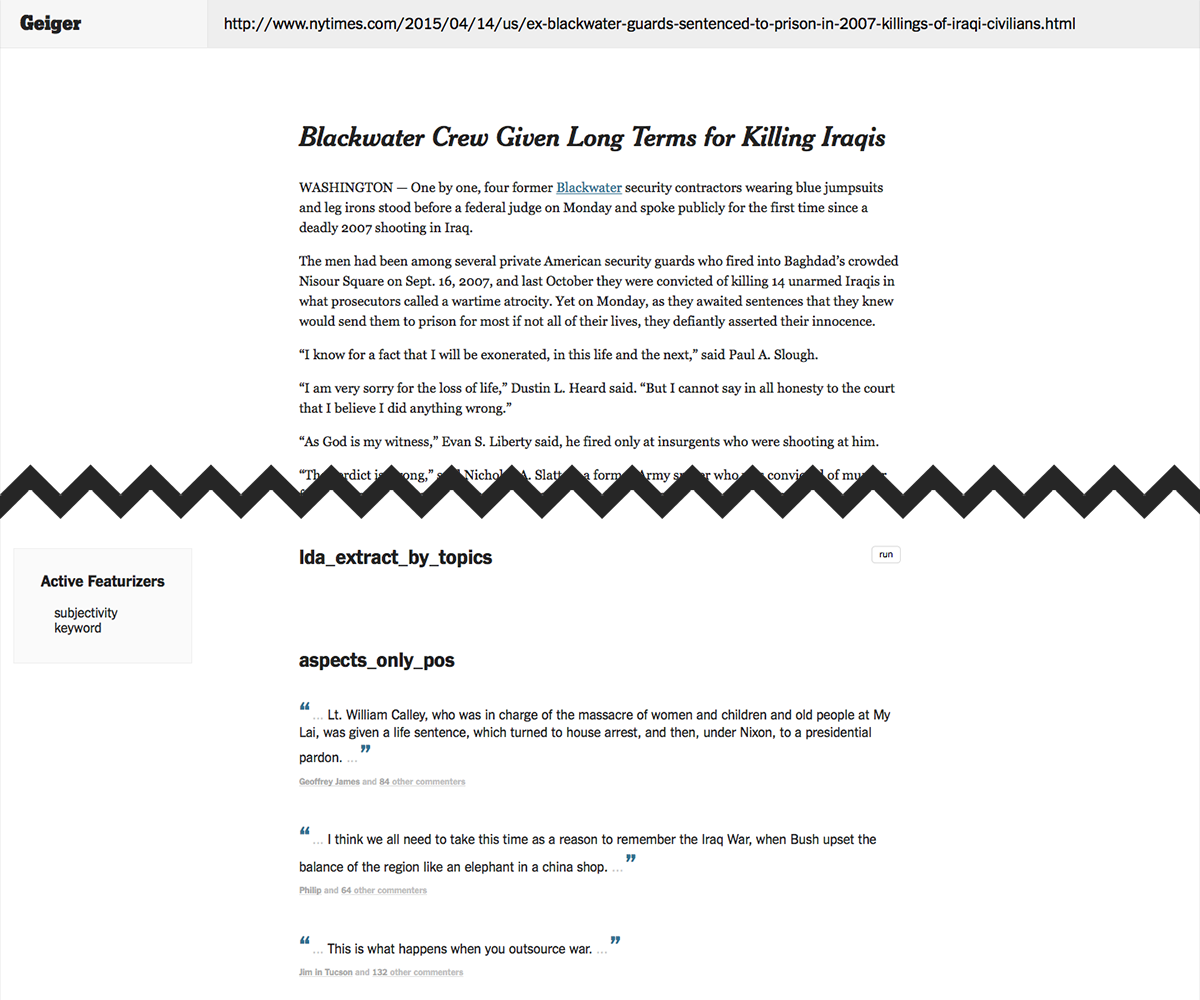
Geiger

For a year I worked on a project called the Coral Project, which is a joint venture between the New York Times and the Washington Post. Online communities and social media are notorious for toxicity and massive levels of noise. There is a saying, "don't read the comments", because supposedly there is nothing of value there. Or what is of value is drowned out by all the awful things others say.
On many sites however, especially the New York Times, there are often insightful and interesting comments. Someone with an experience similar to what's being reported on might offer some additional perspective, for instance. More typically however is that many people will make a comment similar to something that's already posted. That's not inherently an issue, but it does mean that should you read the comments you'll have to wade through many repetitions of the same point.
Part of the draw of comments is to see how people are reacting to an article. But how can you do that without dealing with these downsides of comments?
I worked on building a tool that could draw out the value of comments while leaving the nasty parts behind. Something that used machine learning to summarize the general reaction to an article. Here, machine learning is applied as a sort of advance guard for you, to absorb the offensive and useless comments on your behalf, so you only get the good stuff.



Argos

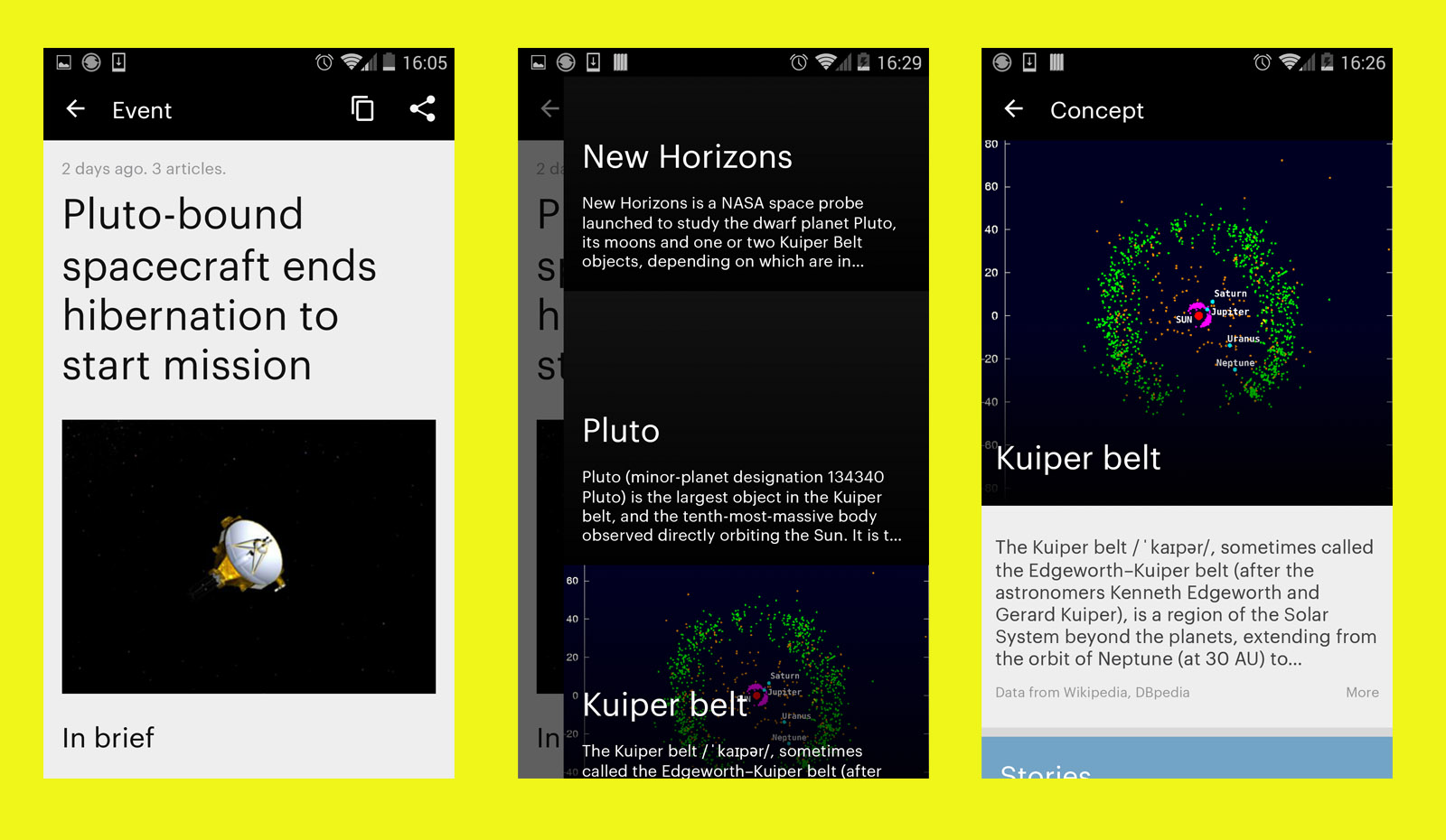
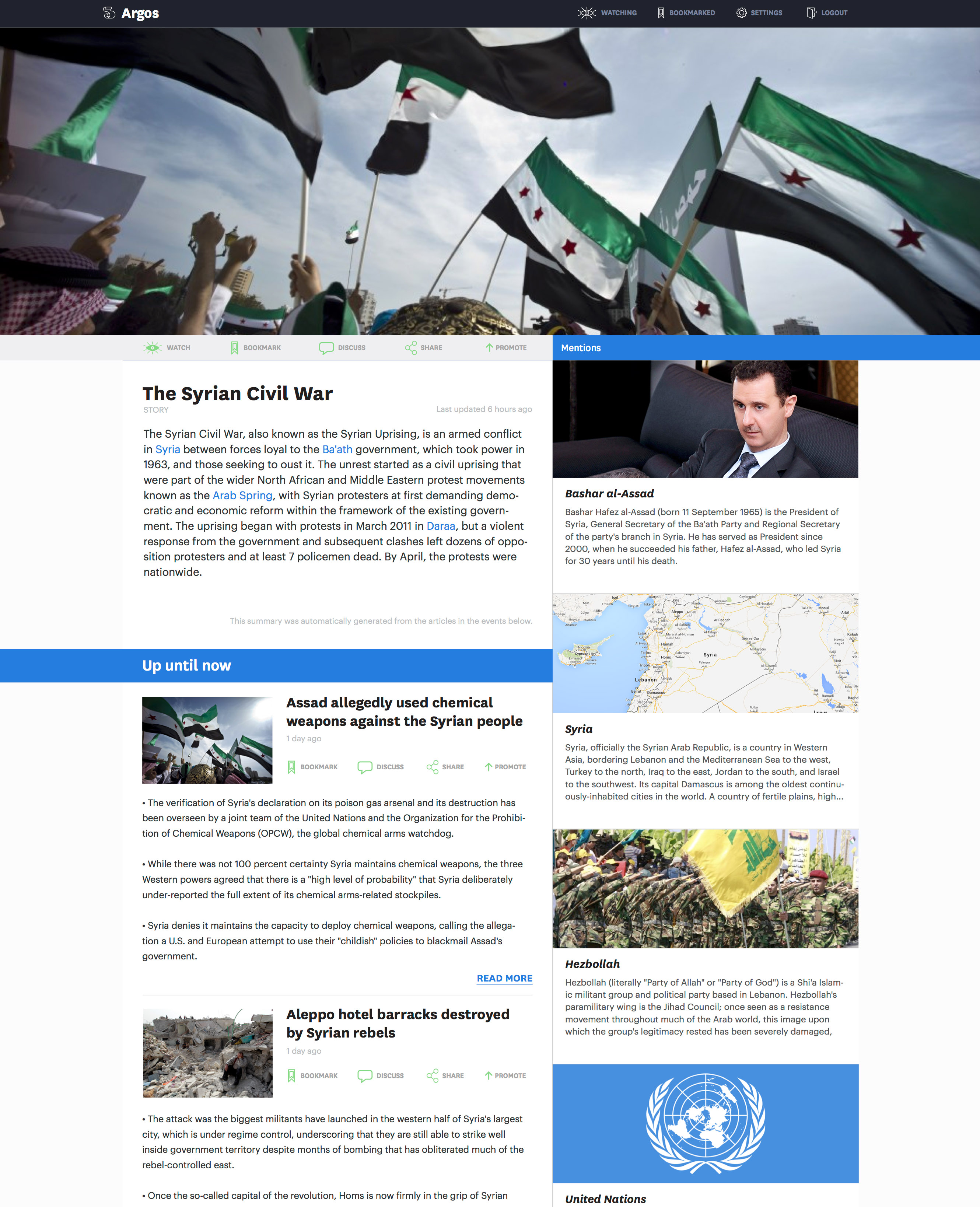
Prior to Geiger I worked on a project called Argos, which applied machine learning to managing information overload.
The premise was that news reading habits may be sporadic - during times of less work, you might read news more regularly, and then drop off if you get busy. The habits of news publishing, however, do not accommodate these fluctuations. The news just keeps on coming at its regular pace, regardless of how busy you are.

Shortcomings
I want to end on a slightly different note. A lot of my interest in machine learning is around where it fails or where it is misused.
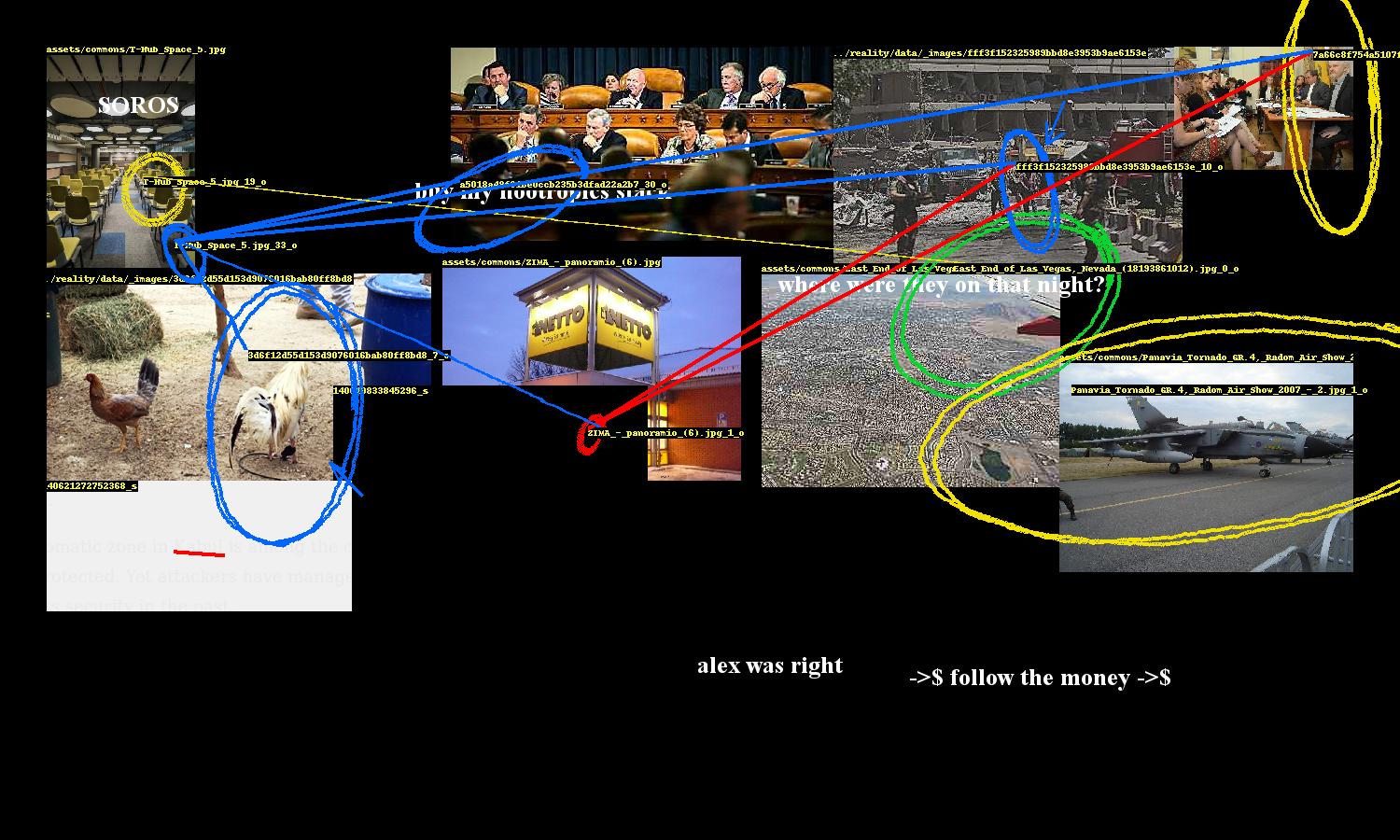
So at some fundamental level, machine learning is about identifying patterns and relationships across features of a dataset. Sometimes it seems to identify these patterns as well as a human might. Sometimes "seems" is the keyword, and the patterns might look correct for some data, but not all. This is to say that machines can misidentify patterns, just like a human can. This phenomenon is called "apophenia" - seeing patterns where there are none. For example, seeing faces in cracks in the wall or coming up with conspiracy theories.
I wrote a bot which uses a state-of-the-art, off-the-shelf object recognition model to parse through images in the news and archives to see what patterns it can find. It will mark up collages of these images that contain patterns it's confident about. This is meant to demonstrate that machine learning is still quite susceptible to errors and just like humans is capable of making mistakes. So we assume machine learning algorithms find some objective truth better than humans at our own peril.
Adversarial machine learning

There is a whole subfield of machine learning focused on how machine learning fails, and how it can be induced to fail, called "adversarial machine learning".
I won't go into too much detail here, but it's a good point of discussion.
Most of the research focuses on machine vision and how the introduction of some calculated noise, even just one pixel, can completely throw off state-of-the-art object recognition models where the correct answer is still stunningly obvious to a human.

I come from a background of design and software development. I started out at IDEO doing interaction design, interactive prototyping, and digital experiments out in the Bay Area and here in New York. At that time we were experimenting with chat bots and chat interfaces long before anyone else. Eventually I made my way into machine learning after becoming interested in how natural language processing could be used in journalism, and also how it could be used in some of the tools we were designing at IDEO. Eventually I left IDEO to prototype some of these news applications, and then found myself working on the Coral Project, a joint venture between the New York Times and the Washington Post, applying machine learning to community moderation and understanding. So my interest in machine learning has long been rooted in how it interfaces with people directly, and how it's used to communicate.